Sunday, August 11, 2013
Thursday, August 1, 2013
Pipi Ideas
As a test, I've launched a site where you can now submit your ideas for what you think should be in a perfect pipeline.
Have a look, vote on what you like, submit what you miss and get it done before I take it down.

Have a look, vote on what you like, submit what you miss and get it done before I take it down.
Super Generic Folder Layout (SGFL)
Had a vision yesterday evening. A vision about how file handling could get more generic and less hard-coded.

Solution
Previously, I've been thinking that each type of entity, like an asset or a sequence, could only have one type of child - assets have variants and sequences shots - so that there would be some structure in how the users worked.This is very constrained however and will not apply to how everyone works and might be rejected by those who don't.

I'm thinking of generalising file management enough so that it basically acts like other file management app -Explorer on Windows versus Finder on OSX - where you can create any folder under any entity - like a shot under a job directly, skipping the sequence-parent. Or any random folder wherever.

We could store that in a preset. So that for their next similar job, they could hit "Add by preset" which makes an empty shell identical to the one they saved.
Next time, they could enter that type and it would use their previous template.
Making Dashboard more into the explorer enforces the one benefit of using the Dashboard over the explorer - Name conventions and placing of files and folders. That's what they get and that's what the Dashboard is supposed to take care of.
Where's the structure then?
Presets
Once the user has created a project shell, like 1 sequence and 1 shot, they have essentially specified how they've chosen to structure their work.We could store that in a preset. So that for their next similar job, they could hit "Add by preset" which makes an empty shell identical to the one they saved.
Templates
To expand on the pre-built types, like shot, asset or sequence, by letting users enter any type as the name, setting properties on their new type, and then saving it as a new type.Next time, they could enter that type and it would use their previous template.
Bottom Line
Making Dashboard more into the explorer enforces the one benefit of using the Dashboard over the explorer - Name conventions and placing of files and folders. That's what they get and that's what the Dashboard is supposed to take care of.
Benefit
More generic means more flexible. Advanced users will like it more and our development would get drastically simplified.Disadvantage
More generic means less rigidity which may be counter-productive for new users who may need more hand-holding. But, this is where presets and templates would step in.Wednesday, July 31, 2013
Alpha
Since heading off to StartupWeekend #London on the 12th of July 2013, Pipi has been featured in Campaign Magazine and PRWeek, gotten a website, a Facebook and Twitter account but most importantly - I now have a team.
We're a hacker, hustler and designer fulfilling the three D's of responsibility - Design, Data and Distribution - and we've been hard at work trying to figure out how to deliver the first pass of Pipi to you guys.

We're a hacker, hustler and designer fulfilling the three D's of responsibility - Design, Data and Distribution - and we've been hard at work trying to figure out how to deliver the first pass of Pipi to you guys.
 Alpha
Alpha
For the Alpha version of Pipi, I'm envisioning two separate tools for File Handling and Metadata respectively.

Perfect File Handling
As we started to collect feedback from various studios (the deep pockets), technical artists (the integrators) and artists (our end-users), it became clear very early that the first step towards establishing a foundation within a production would be to properly manage their file-system.
Files are super important in any sort of work, especially so in an environment with potentially thousands of files generated, created and modified on a daily basis by the many people throughout a production.
There needs to versioning, categorisation, metadata and above all - consistency. And then there's the one law that such a tool abides to above all - it must do no harm.
For the alpha, we'll introduce the Dashboard how it solves these matters.
Meta.. what?
A file cannot tell you why it exists. It cannot tell you about where it came from or what it's purpose is. For these matters, there is the concept of Metadata, or "data about data".
One of the first barriers I faced when envisioning Pipi was how to store metadata together with the content I was looking to enrich. As it turns out, this has been done to death in the past and the go-to solution for doing so is to use a database, such as MongoDB.
But to us (you and me), metadata is so much more than just text. Metadata means screenshots per version, reference videos per shot, audio for animators as well as key/value pairs for automation throughout the pipeline. Short text, long text, tables and hierarchies of text, all of that is part of the data about our content.
For the Alpha version of Pipi, I'll introduce Augment and how it solves this in a way which is both easy to learn (no coding required) and infinitely scalable and adaptable (any OS, any content, any data-format, any size)
Thursday, July 18, 2013
What is Pipi.. to the technical artist?
originally posted on tech-artists.org
Beating the bush
Ok, I think it's safe to say that what we're developing is already being developed in several places on this planet and is something that many of you may already familiar with. What we have done is recognize that not everyone has this luxury, especially the little guy. Our goal then is to make the most elegant and beautifully designed solution we possibly can and then make it available to all.
$$$
We love cg. We work with it every day. And whether Pipi is to be distributed for free, as open-source software or in some other way sold will depend greatly on the feedback given here. Our primary objective is for Pipi to grow to be as beautiful as possible so that it may be useful enough for one, ten, or thousands of users. If the way to get there is giving it away for free or selling it on a per-user basis, that's what we're here to figure out. The way we do get there is up to you, me, and all of us together. Starting now.
Our mantra is..
..enable artists. This means building a foundation upon simple ideas. Simple enough so that when a tool fails, you know what to do. Too many times have I experience situations in which the tool, blindly trusted upon, fails - leaving the user helpless and in need of technical support. To truly enable, the user must be given a choice.
Our design is..
..beautiful. We believe frustration degrades productivity. And one of the ways frustration is born is through the way in which we interact with our tools. That is why user experience and its technical implementation bear equal importance to us. Suffice to say, we build [B]from[/B] the user experience, not towards it.
Where we are
We would like to think of Pipi as Process Management, rather than Task Management. This is where Pipi fits in compared to existing Task Management Suites, such as Shotgun and FTrack.
 |
| Task Management vs. Process Management |
Development
We love agile development methodologies and the lean startup method and recognize that no process is a linear as this. Thats one of the reasons why we're here. Our initial goal is for Pipi to become useful to 1 studio, reasonably small yet know what they want and how to go about doing it manually. We are on the lookout for one that is interested and fits the role of the earlyvangelist.

From there, development will orbit around what is most urgent to them. We will then branch outwards into a closed-beta. A cycle which we'll repeat for each of the main development areas - foundation, usability, tools - until we then move on to the next area of application - Pre-production, Animation, Post-production - covering aspects from Animation, VFX and Games as separate beasts.
I've tried to illustrate this process
 |
| (click to enlarge) |
Benefits, not features
- Dashboard (previously "Launcher")
- This is what each user of Pipi will be most familiar with. It serves as an entry point for each artist at the start of each new day. It is where the user specifies what to work with and in what application. The Dashboard then sets up the environment and runs the application.
- Editor (previously "Creator")
- When creating active (aka working-state) assets or shots, the Editor is where metadata is entered.
- Library
- For browsing available assets
- Publisher
- For creating an inactive (aka published) asset
- Inspector
- For exploring metadata and events
- Manager
- For loading and modifying instances of assets from within a DCC application, such as Maya.
- This is what each user of Pipi will be most familiar with. It serves as an entry point for each artist at the start of each new day. It is where the user specifies what to work with and in what application. The Dashboard then sets up the environment and runs the application.
- When creating active (aka working-state) assets or shots, the Editor is where metadata is entered.
- For browsing available assets
- For creating an inactive (aka published) asset
- For exploring metadata and events
- For loading and modifying instances of assets from within a DCC application, such as Maya.
From here, we will move on to more complex benefits, catering to extensibility and debugging followed by in-the-dirt tools used by artists in specific disciplines, such as utilities for the animator or setup artist.
Illustration here
 |
| (click to enlarge) |
I'll hold off showing you actual designs and prototypes until next time. TMI! TMI my friend! :)
Let me know what you think!
Best,
Marcus
FAQ
Wait, who the hell are you?
My name is Marcus Ottosson. I've been making beautiful cg since 2008, time spent at over 10 vfx studios across Europe ranging from commercials to feature film to idents to triple-A game cinematics.
The video on your website doesn't contain all of the information I need
It doesn't. But we hope it provides you with enough of an introduction to understand our initial goals.
Isn't this basically Shotgun?
No. Shotgun connects people. Pipi connects the software that people uses.
Python, python, python
Yes. We develop with Python and Qt.
I'm using software [X]. Will it be supported?
Where there's a will there's a way. We've been successfully prototyping with Maya and Nuke and aim to cover all of the packages that you use. Let us know what is important to you and we'll move it higher on our checklist.
What about a database?
Yes, who needs 'em. Pipi runs under the Unix philosophy "Everything is a file". That, coupled with a technique similar to the localised metadata storage used by OS X (.DS_Store), help keep the guts of Pipi simple and logical with very small learning curve.
How about version control?
I'll have to rely on you to light the way in this regard as I have no experience with Perforce or other any off-the-shelf solution to binary media revision control, nor have I heard or seen of any DCC house (besides in games) that make use of it.
Will we have to reformat our folder structure to work with Pipi?
No. Our mantra is "Enable Artists", rather than "Enforce Artists". Pipi wraps any existing layout you might have (given it is logical) and provides a unified way of accessing content through code rather than static filepaths.
I need more information
Just ask.
Saturday, July 6, 2013
New Market
When developing a product, the choice of market boils down to these three alternatives[1].
You've got the existing market in which shops such as restaurants are established. The rules of the game are known, customers know what to expect and plenty of resources are when looking to establish one.
There is the re-segmented market. A niche market in which a specialized product within an already existing market aims to change the rules of the game, such as the iPad. The customer knew what they had before and can be told about how why they should get this instead of that.
References
1. Four Steps to the Epiphany by Steven Blank
Existing
You've got the existing market in which shops such as restaurants are established. The rules of the game are known, customers know what to expect and plenty of resources are when looking to establish one.
Re-segmented
There is the re-segmented market. A niche market in which a specialized product within an already existing market aims to change the rules of the game, such as the iPad. The customer knew what they had before and can be told about how why they should get this instead of that.
New
Lastly there is the new market. Here, the solution to the problem is unique and in some cases people aren't aware of ever having the problem in the first place, like with cloud computing. The main issue with this type of market is that it takes a considerable amount of time to get customer adoption. Since they went along just fine without you in the first place, you'll have to come up with something appealing enough for them want to replace it with one or more of their currently used products, like the iPhone did with phones and the PDA.
What about Pipi?
It doesn't fit in either one of those. Instead, the product does exist, the population knows how to use it and how beneficial it is only no one is taking the time to develop a product that is available for everyone.
Remember the Sports Almanac from Back to the Future II? Marty went to the future and got that almanac, which contained sports statistics between the 1950s and 2000. Back in the 80s, he could then use those statistics to win safe bets on any sporting event up until the new millenia. Pipi is similar to that. I've been to the future and not only seen the many benefits available but also applied them to my own work and now I'm back, in the real world, forwarding my experiences to you via my own design. Doing so within a market without competition and plenty of demand. For what more could I ask?
References
1. Four Steps to the Epiphany by Steven Blank
"Everything is a file"
One of the defining factors about UNIX operating systems is it's use of files for everything[1]. Documents are files, images are files, but also processes and hardware such as the running session of Maya and your keyboard.
Folders are treated as files. They have a name, and extension and basic metadata such as dates and original author. In a file, content is a stream of bytes whereas in folders it is the files that it contains and Pipi accesses these folders as though they were files.
While folders provide a common logical interface, they do come at a price. Traditionally, the metadata of files are stored in separate database structures, such as MongoDB. This separates the binary and metadata information of entities to where they can both perform at their best. Accessing hundreds of thousands of properties via the database model is many times faster than that of accessing it via individual files on disk.
Universal Namespace
Accessing an image on Linux can be done by traversing to the directory in which that image resides and then read or write to it. Accessing a process can also be done by traversing to the directory in which the process resides and then reading or writing to it.
/home/image.png
/proc/photoshop
Now, clearly your brand new floppy disk drive is not a file. It's a collection of components physically soldered together in some factory in Utah. What Unix provides however is a unified mechanism for accessing the hardware in your PC and the documents on file-system. Lets look at an example.
Reading from a text document involves launching Notepad and giving it the file you wish to read. Writing to it involves much the same process, only this time Notepad is giving the filesystem something. Accessing the contents of your Shadows of Darkness Disk 6 involves in much the same way handing the file over to the appropriate reading mechanism and overwriting in turn means giving your Full Throttle Disk 54 to the writing mechanism of your original diskette. Makes sense? Of course it does. Lets move on.
Now, clearly your brand new floppy disk drive is not a file. It's a collection of components physically soldered together in some factory in Utah. What Unix provides however is a unified mechanism for accessing the hardware in your PC and the documents on file-system. Lets look at an example.
Reading from a text document involves launching Notepad and giving it the file you wish to read. Writing to it involves much the same process, only this time Notepad is giving the filesystem something. Accessing the contents of your Shadows of Darkness Disk 6 involves in much the same way handing the file over to the appropriate reading mechanism and overwriting in turn means giving your Full Throttle Disk 54 to the writing mechanism of your original diskette. Makes sense? Of course it does. Lets move on.
What about Pipi?
Pipi likes this way of handling data. In addition to every asset that you create being a file, so is its users and running processes. So is its metadata and so are its events. This ensures that we can completely bundle components together without worrying about handles to external entities such as database entries or memory addresses. Moving an asset to another project? No problem, anything related to that asset is safely stored within its own hierarchy of files and folders.
The Unix "Everything is a File" isn't great with metadata
This is true. In Linux, the floppy disk is a mere file and a file-system only allows so much metadata to be appended to it. The date at which it was modified, its author and perhaps even a tag if you're lucky. This forces developers to use an alternative approach for its data about data, such as XMP information in photographs, which strays from the universality of everything in fact being files.
In Pipi "If it isn't a File, it's a Folder"
Pipi solves this by adding another dimension to files; parents. By storing something abstract, such as a user or process, as a folder instead of a file, we can append files, or even more folders, within. These files may represent XMP information, images or settings for that particular piece of data.
Folders are treated as files. They have a name, and extension and basic metadata such as dates and original author. In a file, content is a stream of bytes whereas in folders it is the files that it contains and Pipi accesses these folders as though they were files.
Advantages
Using folders for files has several advantages, the main one being uniformity and ease of use allowing less of a learning curve for developers and a lower rate of error. Another benefit is the modularity it provides. Logical entities can easily be compartmentalized and transferred without any loss of related information.
Disadvantages
Conclusion
While performance is an important factor in any activity, the encapsulation and uniformity provided by this approach is hard to overlook. When one thinks performance, we usually think about one of three things; it is either responsive, sluggish or a long-running process. It is therefore important to consider the environment in which your application runs and whether or not the plausible numbers in a high-activity situation require you to jump through hoops or whether you can direct your focus towards simplicity and stability instead.
In the case of Pipi, the domain for which within creative studios of a 1-100/ppl crew, activity peaks at three times during the day; in the morning (when artists all load up their scenes), during lunch (when long-running processes such as renders or pointcaching are set off) and at 6 pm (when everyone either saves their work or sets of an even longer running process for execution during the night). Since digital content is quite heavy on the file-size front, the master bottleneck in all three of these scenarios is the read/write performance of the server and in the case of a 100 people crew, a low amount of file accesses might hover around 1 read/sec (giving the crew a gentle amount of 2 min from sitting down to start working), a vanilla amount around 3 reads/sec and in busy situations around 50 reads/sec.
Mind you these numbers are mere expectations at this point and via the power given by the ease and usability of this approach, unexpected ways of accessing this data is bound to be discovered and in cases where file access does reach into the hundreds of thousands per second, the user will simply have to wait a few milliseconds before he or she can continue working.
References
Saturday, June 29, 2013
Finding a Common Language of Design pt. 1
It dawned upon me quite early that to design several interconnected parts of software, they would have to share a common language in terms of how they looked and behaved. Luckily, the default look and feel of an application developed under any operating system using Qt is identical to other applications built under the same operating system. It mimics the window frame, the drag and resize facilities, closing and minimizing behaviours and also, colors and sound. In fact, developing with Qt provides promise of "write once, run everywhere", or WORE, meaning that whatever you write will not only work on any platform, but also mimic the look and feel of that platform, while still performing as you designed.
"But then.." I hear you say, "..why not use that to your advantage when developing Pipi?". It's a fair question.
Pipi does not adhere to this flexibility of mimicking its host. This is due to the fact that Pipi is a cross-platform framework. It will be run on a variety of platforms (Windows, Linux and Mac) and thus the behaviour of its host platform will vary but its users, however, won't. Users will come and go and their environments may change, the very platform they work on may change for each project they enroll which is why it is so important to maintain a "beacon of light" and provide a consistent and streamlined UI that any artist can access and use without the slightest doubt of anything being different. Regardless of which platform the artist is working under.
This does not mean, however, that the practices put in place by these hosts are ignored. Throughout the evolution of software, users have come to expect many things from their interaction with computers and it is your responsibility to maintain these expectations if you decide to stray from the path. There is a saying which says that the greatest design is that which behaves just as users expect. This applies to any interaction design, not least so webpages. If you have ever found yourself entering an unfamiliar website with a goal in mind, only to come out of that site with goal achieved 5 minutes later not remembering exactly how you did it but that in fact you did, you have experienced a rare and well-designed site and should take note of its whereabouts and learn from its design. This has happened to me only a few times and sadly, their successfull design makes them the most easily forgettable websites out there. They provide no friction, no moment of wonder or scratching of the head and thus no time to commit this flawless design to memory.
As you might suspect, if you are designing for a fashion site or any other market promoting content rather than functionality, this may not be the best route. For design that evolves around ease-of-use however, focus and simplicity (to borrow from the mantra of Steve Jobs) is key.
"But then.." I hear you say, "..why not use that to your advantage when developing Pipi?". It's a fair question.
Pipi does not adhere to this flexibility of mimicking its host. This is due to the fact that Pipi is a cross-platform framework. It will be run on a variety of platforms (Windows, Linux and Mac) and thus the behaviour of its host platform will vary but its users, however, won't. Users will come and go and their environments may change, the very platform they work on may change for each project they enroll which is why it is so important to maintain a "beacon of light" and provide a consistent and streamlined UI that any artist can access and use without the slightest doubt of anything being different. Regardless of which platform the artist is working under.
This does not mean, however, that the practices put in place by these hosts are ignored. Throughout the evolution of software, users have come to expect many things from their interaction with computers and it is your responsibility to maintain these expectations if you decide to stray from the path. There is a saying which says that the greatest design is that which behaves just as users expect. This applies to any interaction design, not least so webpages. If you have ever found yourself entering an unfamiliar website with a goal in mind, only to come out of that site with goal achieved 5 minutes later not remembering exactly how you did it but that in fact you did, you have experienced a rare and well-designed site and should take note of its whereabouts and learn from its design. This has happened to me only a few times and sadly, their successfull design makes them the most easily forgettable websites out there. They provide no friction, no moment of wonder or scratching of the head and thus no time to commit this flawless design to memory.
As you might suspect, if you are designing for a fashion site or any other market promoting content rather than functionality, this may not be the best route. For design that evolves around ease-of-use however, focus and simplicity (to borrow from the mantra of Steve Jobs) is key.
Product Development as a Film Process
As I was working the other day, it struck me that the approach I had adopted in developing the graphical context of Pipi is very similar to how I would develop the graphical content for Film. In fact, the more similar I made it, the more comfortable and predictable it became. So, if you're familiar film production, I'd like to share this approach with you as it has helped me in materialising my ideas into concrete matter in a rapid fashion.
Firstly, lets have a brief look at what the process of making film looks like today. A director has a vision. The director refines this vision, discusses it amongst his peers and starts materialising his thoughts onto paper in the form of text (the script) and art (storyboards). Then, one or more studios are hired to perform the bulk of work required in turning the director's vision into reality. Starting with more concept art, he then progresses into pre-visualisation in which the film is blocked out in time and space to represent his vision as a kid would when trying to convey his idea using crayons and the surface of your kitchen table. Its crude, its fast and inaccurate. This is when the vision is tested against its target audience, this is where the vision is iterated upon until the foundation is strong. Once a foundation has been built and once the vision is shared amongst everyone involved in its inception, production begins.
Lets stop here for a bit and look how this correlates to product development. An entrepreneur has a vision. The entrepreneur refines his vision, discusses it amongst his peers and starts materialising his thoughts onto paper in the form of text (requirements) and art (wireframes). Then, one or more companies are erected to perform the bulk of work required in turning the entrepreneur's vision into reality. Starting with more wireframes, he then progresses into pre-visualisation.
This is where I at first got stopped in my tracks and gazed out into the horizon, looking for ways to achieve the same fluidity as what has become natural to me when working in film. To "sketch" your vision and to then iterate on this sketch. But how can one sketch in product development? How can a product be tested against an audience without having it actually built? In User Interface and User Experience (UI/UX) Design, there is this concept of wireframing. Wireframing shares many similarities with that of storyboarding. It is a crude and simple, yet clear and fast version that facilitates iteration. UI/UX designers have been using it for years apparently, and it makes perfect sense for interface design just as storyboarding does to film.
The interesting part, however, is what comes next.
In film, once the script has been written, storyboards laid out, it is time to put the vision against the clock and make a so called animatic. The animatic serves as a useful guide to timing and continuity. Do shots fit together in time? Does this sequence make sense when played out like this? How do we go from this shot to this other one? The animatic answers all of these questions and more.
In developing Pipi, the most natural thing for me to do was to apply the same concept of an animatic, but to User Interface Design. So I took my storyboards drawn hastily on paper, refined them in photoshop to look like the product I had in mind and simply animated the UI with a mocked up version of a cursor so as to give the appearance of a user interacting with my future software.
Firstly, lets have a brief look at what the process of making film looks like today. A director has a vision. The director refines this vision, discusses it amongst his peers and starts materialising his thoughts onto paper in the form of text (the script) and art (storyboards). Then, one or more studios are hired to perform the bulk of work required in turning the director's vision into reality. Starting with more concept art, he then progresses into pre-visualisation in which the film is blocked out in time and space to represent his vision as a kid would when trying to convey his idea using crayons and the surface of your kitchen table. Its crude, its fast and inaccurate. This is when the vision is tested against its target audience, this is where the vision is iterated upon until the foundation is strong. Once a foundation has been built and once the vision is shared amongst everyone involved in its inception, production begins.
Lets stop here for a bit and look how this correlates to product development. An entrepreneur has a vision. The entrepreneur refines his vision, discusses it amongst his peers and starts materialising his thoughts onto paper in the form of text (requirements) and art (wireframes). Then, one or more companies are erected to perform the bulk of work required in turning the entrepreneur's vision into reality. Starting with more wireframes, he then progresses into pre-visualisation.
This is where I at first got stopped in my tracks and gazed out into the horizon, looking for ways to achieve the same fluidity as what has become natural to me when working in film. To "sketch" your vision and to then iterate on this sketch. But how can one sketch in product development? How can a product be tested against an audience without having it actually built? In User Interface and User Experience (UI/UX) Design, there is this concept of wireframing. Wireframing shares many similarities with that of storyboarding. It is a crude and simple, yet clear and fast version that facilitates iteration. UI/UX designers have been using it for years apparently, and it makes perfect sense for interface design just as storyboarding does to film.
The interesting part, however, is what comes next.
In film, once the script has been written, storyboards laid out, it is time to put the vision against the clock and make a so called animatic. The animatic serves as a useful guide to timing and continuity. Do shots fit together in time? Does this sequence make sense when played out like this? How do we go from this shot to this other one? The animatic answers all of these questions and more.
In developing Pipi, the most natural thing for me to do was to apply the same concept of an animatic, but to User Interface Design. So I took my storyboards drawn hastily on paper, refined them in photoshop to look like the product I had in mind and simply animated the UI with a mocked up version of a cursor so as to give the appearance of a user interacting with my future software.
 |
| Click to play |
This is great! I can now easily send this off so anyone and, without further explanation, the recipient would understand not only what it looks like and what it can do, but also how those things are done.
Taking this one step further, we can insert the sequence of images into a demo context, such as an operating system, Windows in this case, and host application, Maya.
 |
| Click to play |
As you can see, there are actually two separate user interfaces being demonstrated simultaneously, one spawning the other, while the fictional user clicks his way through the menu items to achieve his goal. Additionally, the video contains some backing explanation to the side of the window, accentuating things not clear from simply looking at the screen.
Using these techniques, I can iterate on an idea I just finished plotting on paper to the level of what you just saw in these videos in less than a day's worth of work each. And at such high level of clarity, I can collect feedback on features, user experience and visual design more accurately and quickly from my target audience, having the next version out the following morning. If not the very same day.
To finish off, I'd like to provide you with one final demonstration. A user experience and feature demonstration of another application that was hastily developed in order to gain the same level of understanding that one of the previous "wirematics" could have provided, except the execution time was closer to two weeks of Python coding.
 |
| Click to play |
What is Pipi
It has taken me a long time to define Pipi. As I made my way from studio to studio over the course of the past five years, each one had this "something" about it that made work a much more pleasant experience. Turning these, usually repetitive and cumbersome tasks, into welcome distractions.
Of the 10+ studios I've worked at, each and every one displayed patterns of the "earlyvangelist". The characteristics are as follows; the earlyvangelist:
I remember this one artist of a mid-sized house here in the UK who told me he had suggested to management that he wanted to build better tools that could help reduce the rate of mistakes and boost productivity of their crew, but the benefits was unseen by management and so never allowed him to proceed.
Management is not to blame, however. It is difficult to visualise the abstract benefits of what you do not know. It reminds me of a famous quote by Henry Ford. "If I had asked people what they wanted, they would have said faster horses." Although fake, its message holds true. It is a trait of human nature to try and improve on what we have by mere optimisation rather than stepping outside of that box and into unfamiliar territory. The territory of innovation.
Developing tools is expensive. Both in terms of money and time. There is an inevitable period of trial-and-error when breaking new ground. But what you get out of this process is invaluable. Not only will it accelerate your rate of delivery, it will enhance it, make it stronger and more accurate. The rate of mistakes will drop significantly and the happiness-factor of your workforce will increase.
_____________________________________________________________________________________________
As I have spent the past year refining this idea and the solutions that came with it, the smoke has cleared and my vision is slightly less blurry. I would now like to give you an overview of what some of my conclusions thus far.
I will now go over the supplied set of tools in more detail.
_____________________________________________________________________________________________

_____________________________________________________________________________________________
 Each job, each asset and each shot come bundled with data. This "data about data" is referred to as metadata, and shots et. al. are in turn known as entities.
Each job, each asset and each shot come bundled with data. This "data about data" is referred to as metadata, and shots et. al. are in turn known as entities.
In addition to visualising data, the Inspector also provides the means to monitor what is referred to as "events". Events are recorded throughout the use of Pipi. Any time an artist comments on a shot, publishes his/her work or playblasts a shot in preparation for dailies, the recorded event can be monitored by other artists. This helps artists working on the same asset or shot stay in sync with each other and makes it easy to stay up to date on the overall progress for each chunk of work.

As you start a new job, the Creator provides the means of adding the necessary sequences, shots, assets and variants into that job. It is in the Creator where you append or remove metadata such as camera information, storyboards, references, audio or video et al. The metadata can then be accessed by artists, other Pipi tools or your custom tools.
Creator is most commonly accessed via the Launcher. Whenever an entity is edited, Creator will appear.
_____________________________________________________________________________________________

The Publisher then acts as the funnel through which each shared chunk of work is passed before it reaches the public space. The publisher will perform sanity-checks (e.g. "is the geometry visible?") on your work to ensure it conforms to the already published work, in addition to help artists meet the required guidelines.
_____________________________________________________________________________________________

Once an artist has published his/her work, it can be found in the Library. The Library provides a birds-eye view of each published entity of each job within a studio. It allows artists not only to load animations, point-caches and assets, but also to perform an at-a-glance inspection of metadata, relations between it and other entities, their history and preview the data directly in the Library. This makes the process of finding what you are looking effortless for any artist.
 The Handler is the only application-specific tool so far. It deals with the specifics of how an application deals with assets, such as rigs or point-caches. To aid in explaining I'll use Maya as case-in-point. In Maya, once an asset such as a rig has been loaded, it provides the user with a few options. Such as whether the asset should be imported or referenced, which version to load and the ability to up- or downgrade assets. Things which makes a difference only within the specific domain in which the artist is working at the time.
The Handler is the only application-specific tool so far. It deals with the specifics of how an application deals with assets, such as rigs or point-caches. To aid in explaining I'll use Maya as case-in-point. In Maya, once an asset such as a rig has been loaded, it provides the user with a few options. Such as whether the asset should be imported or referenced, which version to load and the ability to up- or downgrade assets. Things which makes a difference only within the specific domain in which the artist is working at the time.
I mentioned that it is application-specific. This means that for each application to make use of it, it has to be provided with an implementation. This is due to the alternating ways applications deal with assets. In Nuke, an asset is an image-sequence loaded via its internal nodes known as "Read". Maya can also load image-sequences, but does so via different means. The Handler provides a high-level abstraction from these technicalities that can be manipulated via it's user interface so that the artist only has to focus on the "what" and not the "how".
Initially, the Handler will be provided for all major DCC applications, such as Maya, Softimage and Houdini, along with Nuke and Mari.
With these tools at hand, an additional set of tools are being developed. Such as a relational viewer to display relationships between the entities within a studio, a rigging framework including "weightshift" and an animation library utilities for storing poses and reusable segments of animation.
Hope you enjoyed and thanks for your attention.
Of the 10+ studios I've worked at, each and every one displayed patterns of the "earlyvangelist". The characteristics are as follows; the earlyvangelist:
- Has a problem
- Is aware of having a problem
- Has been actively looking for a solution
- Has put together a solution out of piece parts
- Has or can acquire a budget
I remember this one artist of a mid-sized house here in the UK who told me he had suggested to management that he wanted to build better tools that could help reduce the rate of mistakes and boost productivity of their crew, but the benefits was unseen by management and so never allowed him to proceed.
Management is not to blame, however. It is difficult to visualise the abstract benefits of what you do not know. It reminds me of a famous quote by Henry Ford. "If I had asked people what they wanted, they would have said faster horses." Although fake, its message holds true. It is a trait of human nature to try and improve on what we have by mere optimisation rather than stepping outside of that box and into unfamiliar territory. The territory of innovation.
Developing tools is expensive. Both in terms of money and time. There is an inevitable period of trial-and-error when breaking new ground. But what you get out of this process is invaluable. Not only will it accelerate your rate of delivery, it will enhance it, make it stronger and more accurate. The rate of mistakes will drop significantly and the happiness-factor of your workforce will increase.
_____________________________________________________________________________________________
As I have spent the past year refining this idea and the solutions that came with it, the smoke has cleared and my vision is slightly less blurry. I would now like to give you an overview of what some of my conclusions thus far.
What is Pipi?
Pipi is a Digital Content Creation (DCC) framework for the film, commercial and games industries.Why Pipi?
Digital content creation is rapidly getting more and more divided into areas of special expertise and along the way we have forgotten to keep the pieces in sync. Pipi aims to solve exactly that.How does it work?
Pipi is a framework. It provides you with an essential set of tools along with a foundation upon which to build your own tools that fit into your studio's unique way of working. It integrates with the major existing applications, such as Maya and Nuke, and frameworks delivered by third-party developers, such as Shotgun and FTrack, to help take the hassle out of fast-paced production development.Tools?
Pipi ships with six essential tools that serve as pivot-points for your work and own custom tools development. These tools, in order of relevance, are Launcher, Inspector, Creator, Library, Publisher and HandlerI will now go over the supplied set of tools in more detail.
_____________________________________________________________________________________________
Launcher
Main entry-point for artists. This is what is booted up at the dawn of each day as artists begin their work. It supplies artists with an overview of each project and its content along with the ability to manage projects from a higher-level point of view; creating sequences, editing assets, removing shots is all performed via the Launcher.
_____________________________________________________________________________________________
Inspector
 Each job, each asset and each shot come bundled with data. This "data about data" is referred to as metadata, and shots et. al. are in turn known as entities.
Each job, each asset and each shot come bundled with data. This "data about data" is referred to as metadata, and shots et. al. are in turn known as entities.
As the number of entities grow, metadata helps to keep things organized. To give an example, it can be used to keep track of frame-ranges in a shot, comments in playblasts or artist-supplied descriptions for assets. The Inspector then provides the means to visualise this data.
In addition to visualising data, the Inspector also provides the means to monitor what is referred to as "events". Events are recorded throughout the use of Pipi. Any time an artist comments on a shot, publishes his/her work or playblasts a shot in preparation for dailies, the recorded event can be monitored by other artists. This helps artists working on the same asset or shot stay in sync with each other and makes it easy to stay up to date on the overall progress for each chunk of work.
_____________________________________________________________________________________________
Creator

As you start a new job, the Creator provides the means of adding the necessary sequences, shots, assets and variants into that job. It is in the Creator where you append or remove metadata such as camera information, storyboards, references, audio or video et al. The metadata can then be accessed by artists, other Pipi tools or your custom tools.
Creator is most commonly accessed via the Launcher. Whenever an entity is edited, Creator will appear.
_____________________________________________________________________________________________
Publisher

I mentioned that in a studio, work is divided into chunks and that each chunk is delegated to specialists. These specialists communicate with each other by "publishing" their finished material onto a central database. Other specialists can then access this material knowing that it conforms to a fixed set of studio rules. Background props, for instance, may have to conform to a certain polygon-count, character setups may have to provide a certain set of controls familiar to animators and so on.
The Publisher then acts as the funnel through which each shared chunk of work is passed before it reaches the public space. The publisher will perform sanity-checks (e.g. "is the geometry visible?") on your work to ensure it conforms to the already published work, in addition to help artists meet the required guidelines.
_____________________________________________________________________________________________
Library

Once an artist has published his/her work, it can be found in the Library. The Library provides a birds-eye view of each published entity of each job within a studio. It allows artists not only to load animations, point-caches and assets, but also to perform an at-a-glance inspection of metadata, relations between it and other entities, their history and preview the data directly in the Library. This makes the process of finding what you are looking effortless for any artist.
_____________________________________________________________________________________________
Handler

I mentioned that it is application-specific. This means that for each application to make use of it, it has to be provided with an implementation. This is due to the alternating ways applications deal with assets. In Nuke, an asset is an image-sequence loaded via its internal nodes known as "Read". Maya can also load image-sequences, but does so via different means. The Handler provides a high-level abstraction from these technicalities that can be manipulated via it's user interface so that the artist only has to focus on the "what" and not the "how".
Initially, the Handler will be provided for all major DCC applications, such as Maya, Softimage and Houdini, along with Nuke and Mari.
With these tools at hand, an additional set of tools are being developed. Such as a relational viewer to display relationships between the entities within a studio, a rigging framework including "weightshift" and an animation library utilities for storing poses and reusable segments of animation.
Hope you enjoyed and thanks for your attention.
Friday, May 31, 2013
Folder Layout pt. 3
A Better Way
Wouldn't it be great if we could avoid separating any data at all? If all data could live happily under the same roof?
The end goal is to simplify data navigation. You want to be able to locate what you need as quickly as possible. As we have seen, some data may be logically paired with other data and so a hierarchical approach may seem like a good idea. Other data however provide a less rigid constraint towards its source, such as a user and his shots, and may perhaps be better suited for tagging and filtering. A user working on a shot deals with the shot "entity", various rigs and output pointcaches supporting assets such as audio, images, notes, feedback and so on. The user does not care whether some data are stored in one location and some are not, the user only wishes to quickly retrieve the data he needs at the time he needs it whilst still being able to work on the physical files his chose application. We would like to find one unified way in which all of this is possible.
A closer look at the previous example reveals some more superfluous use of structure.

Some data within a cg production however have no binary data, and yet contain metadata as well as other pieces of data. Consider an asset such as the Simulation Setup for a Ladybug. The rig has no binary information related to it, it is "abstract", yet it contains versions in which binary information are stored. Each version in turn has metadata, such as date of creation, author and changelog and so on.
At the root, we have an item referred to as Studio. The studio contains everything related to a studio as a whole. This includes jobs, users, settings, running processes and so on.
Each item hosts information relevant to its type. Job holds data relevant to a single job. This includes all sequences and shots, assets, users working on this job and related metadata such as who the client is, when the job is due, media such as storyboards, reference images and videos.
Moving forward, we have the Asset which contains everything related to a single asset, such as a Character. This includes models, textures, rigs, shaders and associated data and relationships to other data.
Certain types of objects are designed to host certain other types of objects.

In this example, the job beast is host of the items work and published. From a users perspective, when mining a job for resources, be it assets or which shot to get on working with next, this is all that is required at this level. On disk however, beast may host a multitude of items other than its resources.
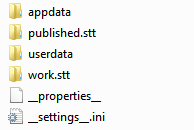
The items appdata and userdata host application-specific data and users home directories respectively. Note the extensions. These are rather ugly too look at and would be better represented by icons other than the default windows explorer ones. Certain names also contain reserved keywords. In this case, __properties__ host generic metadata about beast and __settings__.ini contains user editable data, as hinted towards via the .ini extension.
The various types required to make up a studio and all of its resources can grow quite large, that's why it is important to structure it in an as manageable form as possible.
Firstly, lets look at some of the assumptions we can make about the users of Pipi.
The target goal is to facilitate the creation of CG images and as such the major components can be broken down into Sequences and Shots, each shot capable of having one of more Assets.
Assets include elements such as Characters, Props, Vehicles, Set Dressing objects etc. Each Asset may contain additional elements per department. I'll bring in Bob and the Ladybug project from the previous post to aid in the explanation.
Bob works in modeling on the hero character Ladybug. Ladybug has got several models associated with it, such as the body, the face, character-specific props such as clothing, a wristwatch and so on. Whatever model Bob eventually finishes, since Bob is in the Modeling Department, his published material will go under the department category Modeling.
When Bob works on the body model in Maya, Bob saves his scene every now and then. Generally, Bob will only share material with other departments once he is happy with his results and so application files, such as scene versions, are stored separately from those happy results. This helps keep the database clean and minimal, whilst still allowing Bob to make as many revisions to his scene-files as he needs. This results in the following hierarchy.

Monday, May 13, 2013
Auto Rigging pt. 1
A somewhat overloaded term. What does it actually mean to "autorig" something? Firstly, let's look at why one would consider autorigging for their project.
Hold on there. Even though the end result is to have an intutive control rig for the animator, the way to get there is often different with each artist. Before deciding whether to automate something, it is important to understand exactly what it is you wish to automate and such information is best taken from experience. If you're thinking "I dislike rigging and want to automate it in order to get it out of my way" you're reading the wrong post. Once you know what to do, you must also understand it. Remember, you can't design what you don't understand.
Lets have a look at another video, this time the video has been sped up only two times, is half as long and contains twice as many features on four times as many limbs as the previous video.
Why?
Lets have a look at a simple task, such as setting up forward kinematics controls for an arm.
The video is sped up 5x and takes about two minutes to play out. Its quite the task! Also, note that after the joints have been drawn, no new information is added. The joints contain both position, orientation and hierarchical information which is all that is required for the subject to behave as expected. Everything past that point is implementation detail, technicalities, that can be automated. Also note that the drawing is the least time consuming process.
I think this will suffice as motivation for automation.
Well, a human usually has two of these along with legs, each side being identical to the other in any meaningful regard. That means that the additional time it takes to also set up the other side is of equal length to the one we just set up, meaning that what you do you'll have to do four times to cover each limb of a character.
Put simply, rigging is a repetative task. The very many things you do for each setup are densly similar to tasks you just did or have done previously. How about a bullet list of some of the main things that automation can help you with?
I think this will suffice as motivation for automation.
What else?
Well, a human usually has two of these along with legs, each side being identical to the other in any meaningful regard. That means that the additional time it takes to also set up the other side is of equal length to the one we just set up, meaning that what you do you'll have to do four times to cover each limb of a character.
Put simply, rigging is a repetative task. The very many things you do for each setup are densly similar to tasks you just did or have done previously. How about a bullet list of some of the main things that automation can help you with?
Symmetry
This is a big one. We can cut out job in half if one side simply followed the other. Even if your characters suffers from asymmetry, such as zombies, chances are that features are still to be repeated to the other side.Common features
Many things have been done before and works. Automation could keep you from reinventing the wheel more than onceTime well spent
Time spent repeating is time wasted and nothing hinders creativity more than that of wasted time. You'll spend half the time performing repetative tasks and the other half thinking of ways around those tasks. Not having to worry about things already solved will allow you to focus on moving forward and make things better and faster.Ok, let's get crackin'
Lets have a look at another video, this time the video has been sped up only two times, is half as long and contains twice as many features on four times as many limbs as the previous video.
What happened there?
As you can see, the result of this video is the same as the previous video, and more, in less time. What is missing from this video are things that have been automated based on the initial drawing of the joints along with their naming schemes. Remember, anything beyond that point is implementation detail and is repetative with each setup. Once you know how to setup forward kinematics, the same rules apply for each and every forward kinematic enabled setup you do and the same goes for inverse kinematics, twisting, bending, stretching, pinning, space switching and so on.
Currently working on this tool, the next incarnation will do more without requiring any more work from the user. Thats the beauty of automation.
Wednesday, March 13, 2013
Folder Layout pt. 2
Keeping your socks in your boots
It may be very beneficial to ensure that all data related to any other data are kept together. Like sequences can contain shots, a shot may contain more than simply the users working directories, such as its description, length, padding, camera information, frame rate, media such as video-references for animators or audio for lipsync.
Tools already exist for this purpose. Some examples I already mentioned in the previous post but I'll repeat them here for completeness.
I really recommend checking those out, they've got videos showing some fundamental functionality and they are used today by hundreds of studios. I'll refer to these tools as Offline Asset Management, or OFAM for short. They provide two major concepts rolled into one - tracking assets and shots along with assigning tasks and maintaining schedules of projects. The tracking part enable users to associate data that would otherwise be difficult to associate via a simple hierarchy of files and folders, along with the ability to add links other than simple hierarchical ones, such as their relationships to users or even other data in the database. They do this by separating the binary data from its related information.
 |
| Separating binary data from related information |
The caveat of this approach however is that it is external to the files they augment. Augmenting data, aka Metadata, is stored separately from their associated assets, shots and sequences in a database table such as SQL.
This means that whenever a change happens on one side, the other side needs to get updated somehow. This introduces the concept of syncing and is generally handled like this - a change in Maya, say a publish of a character, will trigger an event (referred to as a callback) which performs the corresponding action on the server. Data generally only travels in this one direction as any change in any of an objects metadata, such as shot description, has no relevance within, in this case, Maya (or does it? I'll dive into this more later!). For example, a new asset is created from Maya. Maya triggers a callback and the equivalent asset is created within the OFAM.
 |
| Psuedo-code of mirrored command |
Some data will remain unique on either end, such as the binary scene file, while other data, such as camera information, will overlap and cause duplicity.
 |
| Overlapping data means duplicated data |
In order to store the camera information of a shot, the shot itself and all of its related hierarchy must exist within the database, if only to host that information, so that users have a way to associate it and to search for it. However the hierarchy must also exist to host the binary files.
While the overlap is very small in terms of megabytes on disk, we aren't concerned with disk space issues. What matters is the information they represent and our ability to efficiently find it.
The overlap applies to both shots, sequences and assets and also any media associated. Some media are only accessible via the OFAM, such as a reference material, thumbnails, playblasts etc., but must yet be stored in binary form somewhere on disk. This means that you end up having an additional hierarchy of binary files, besides the original binary files themselves.
 |
| Superfluous complementing data |
Tuesday, March 12, 2013
Folder Layout pt. 1
In a perfect world, the user will never have to know that there ever was a hierarchy of files on some disk. What matters is the data and it's level of discoverability.
Technically though, files and folders are still the most efficient way of storing heavy data on disk and so for a tool to successfully hide the details of that implementation, great care must be taken when considering their layout. A cg production generally consists of thousands or hundreds of thousands of files, some of which are tightly related, such as sequences of images, and others which relationship is less obvious, such as which animation is using which character setups.
That is why it is important to consider exactly what files will exist within this hierarchy and exactly how they relate to one another. Lets dive in with some examples.
Sequences may contain shots, shots may be worked on by one or more users and on those shots users may work in one or more applications.
 |
| Balance readability with duplicity |
You may find it odd to couple sequence and shot, that seem quite obviously interconnected, with that of user and application, but later I'll head into more details why they can come in handy in parts of the tool that deals with a users sandboxes and working spaces. The ideal layout is the one that produces the most appealing balance between readability and duplicity. In this layout, besides the logical benefits of picturing it in ones mind, practical considerations occur such as removing one shot will results in the users working directory to be deleted as well, which is what the user would come to expect.
Consider to following hierarchy.

In this layout, user is the host of sequences. A project is bound to have more than one user and since shots cannot exist without a sequence, and a film is nothing without shots, it is safe to say that at least one sequence will also exist and thus each sequence would get duplicated underneath each user.
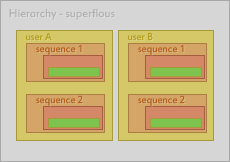
As you can see, "sequence 1" is repeated once for each user which may or may not be desirable. Each shot within each sequence is also duplicated, producing an exponential multitude of duplicates, thus violating our rule of balancing readability with duplicity. A potential benefit of this layout is that finding the associated sequences to a user is as easy as looking at the users folder root. However, minor filtering requirements like these there have other, better, alternatives that doesn't depend on their physical layout on disk.
If you look at the first hierarchy, it also produces duplicates. Underneath each shot is a folder for each user working on the shot. If a user has worked on more than one shot, that folder would have a duplicate under each one. This is where one needs to decide on which approach is better suited for which task, as there will most often exist a trade-off between.
In summary, the hierarchical layout of files can exist in any order. Ideally the more general classes of types, such as shots and sequences, come first, followed by the more specific ones, such as images and pointcaches.
Friday, January 25, 2013
What does a Pipeline actually do?
During the development of my approach to a pipeline, I found myself digging deeper into what it actually is I'm trying to do. Turns out the word Pipeline is heavily overloaded and may be broken down into two parts; Workflow and Organization.
Workflow deals with simplifying tasks, such as how to get this 200 pound gorilla on screen before the deadline, and Organization deals with how data travels between artists during production, such as how the character setup artists deals with updating the gorilla model.
Simplifying Organization
Organization may be broken down further into two additional parts; Production Management and Asset Management. Managing Production is the art of keeping your artists in sync with the needs of production. It involves handing them the information they need in order to do their jobs, such as tasks, feedback and a deadline. It is in control of how social data flows between artists and production.
There are several products on the market today that deals with this aspect of the pipeline exclusively, namely Shotgun, FTrack and Tactic
Requirements
What is required by a Production Management system is rather similar across industries and have a large foothold in history as to how it should be approached. Asset Management however has not.
Asset Management is the art of directing how binary data flows between artists, such as how the gorilla model will get from the modeler to the rigger. Note the difference between this and what is going on in the workflow domain. Workflow governs how artists perform actions whereas Organization is what the actions actually do. Lets take an example
A modeler has finished his first iteration of the gorilla model and wishes to share it with the rigger. The modeler hits "Publish" and writes down a comment. When finished, the rigger opens up the Library and Loads the model.
This is all fine and dandy, but what is actually going on under the hood? What does "sharing" mean in terms of 1s and 0s? What the modeler did was part of the workflow and what actually happened is organizational. As you might suspect, the line I'm drawing between workflow and organization if close to that of Interface versus Implementation. The interface is very similar across various cg studios, artists will always require a way of sharing their work with others, but the implementation however might not be. Sharing might happen using git commits via a central server in Malaysia or it may happen via exchanging floppy disk in the kitchen during lunch.
To sum up, here is the pipeline hierarchy of responsibility
/pipeline
/organization
/production management
/asset management
/workflow
/tools
/best practices
I'll touch on workflow more once I've started implementing it. Now onto how I approached the interface and implementation of an Asset Management system. Pipi is the name. It "acts as a bridge between artists in order to aid collaboration"

Note that there is a subtle difference between simplifying "collaboration" and simplifying "organization". Organization helps Collaboration, not the other way around, and the duties of any pipeline should be to simplify organization, and as such, aid in collaboration. Asset management is one of the components of a pipeline that
The duties of Pipi can be broken down into two major components. It..
- ..manages files and folders
- ..presents relevant information
And it does so via a set of custom-built tools.
I will now go over each of those in more detail.
Let's use the example of The Ladybug. The Ladybug is a hypotetical 10 second animation produced by 10 people in a matter of 10 months. Once the script has been written and the crew picked out, the first order of business is to start creating material.
Once Bob reaches v120, he decides to share his work with his co-workers. After all, Vicky has been expecting it for her Character Setup of the Ladybug.
This is referred to as Publishing
Any artist who wishes to share his or her work must first Publish the material they wish to share. This ensures that all material in the common area align with each other in terms of the various conditions they must fulfill.
This critera is referred to as a Post-Condition
All models in the common area are guaranteed to live up to a set of post-conditions just like this one. The same applies assets of any species.
An Asset is a building-block of a film
It represents an entity, such as a character or a piece of furniture, along with information about that entity, such as its name, description, author and so on. All of it encapsulated into a unified whole, called an Asset.
Assets are at the very heart of Pipi. In fact: A shot can only consist of Assets
This means that before an animator, for instance, can make use of your beautifully sculpted model, it must first go through the rigorous set of tests and fulfill each of the post-conditions set for its species.
This enables artists to know what to expect when loading new material from Pipi and helps keep things neat.
Workflow deals with simplifying tasks, such as how to get this 200 pound gorilla on screen before the deadline, and Organization deals with how data travels between artists during production, such as how the character setup artists deals with updating the gorilla model.
Simplifying Organization
Organization may be broken down further into two additional parts; Production Management and Asset Management. Managing Production is the art of keeping your artists in sync with the needs of production. It involves handing them the information they need in order to do their jobs, such as tasks, feedback and a deadline. It is in control of how social data flows between artists and production.
There are several products on the market today that deals with this aspect of the pipeline exclusively, namely Shotgun, FTrack and Tactic
Requirements
What is required by a Production Management system is rather similar across industries and have a large foothold in history as to how it should be approached. Asset Management however has not.
Asset Management is the art of directing how binary data flows between artists, such as how the gorilla model will get from the modeler to the rigger. Note the difference between this and what is going on in the workflow domain. Workflow governs how artists perform actions whereas Organization is what the actions actually do. Lets take an example
A modeler has finished his first iteration of the gorilla model and wishes to share it with the rigger. The modeler hits "Publish" and writes down a comment. When finished, the rigger opens up the Library and Loads the model.
This is all fine and dandy, but what is actually going on under the hood? What does "sharing" mean in terms of 1s and 0s? What the modeler did was part of the workflow and what actually happened is organizational. As you might suspect, the line I'm drawing between workflow and organization if close to that of Interface versus Implementation. The interface is very similar across various cg studios, artists will always require a way of sharing their work with others, but the implementation however might not be. Sharing might happen using git commits via a central server in Malaysia or it may happen via exchanging floppy disk in the kitchen during lunch.
To sum up, here is the pipeline hierarchy of responsibility
/pipeline
/organization
/production management
/asset management
/workflow
/tools
/best practices
I'll touch on workflow more once I've started implementing it. Now onto how I approached the interface and implementation of an Asset Management system. Pipi is the name. It "acts as a bridge between artists in order to aid collaboration"

Note that there is a subtle difference between simplifying "collaboration" and simplifying "organization". Organization helps Collaboration, not the other way around, and the duties of any pipeline should be to simplify organization, and as such, aid in collaboration. Asset management is one of the components of a pipeline that
The duties of Pipi can be broken down into two major components. It..
- ..manages files and folders
- ..presents relevant information
And it does so via a set of custom-built tools.
I will now go over each of those in more detail.
Managing files
To help users manage files, a separation between `working` and `published` files are introduced.Let's use the example of The Ladybug. The Ladybug is a hypotetical 10 second animation produced by 10 people in a matter of 10 months. Once the script has been written and the crew picked out, the first order of business is to start creating material.
Working
"Hey Bob, can you start working on the ladybug model?"Upon this request, the artist enters a working mode. He opens up the designated software for the Ladybug project, Maya, and starts saving files to his private user directory located under the asset. (more on what an asset is later)
/studio/assets/LadyBug/bob/bobs_ladybugmodel_v001.mbAs time goes, Bob will start gathering quite a large amount of files. That's fine, Bob is currently working within his own sandboxed area and as long as Bob doesn't have any problems with it, neither does anyone else.
Once Bob reaches v120, he decides to share his work with his co-workers. After all, Vicky has been expecting it for her Character Setup of the Ladybug.
Publishing
Bob commits his work to the central repository of files, where anyone can access it. By using tools provided by Pipi, Pipi will ensure that the file lands in a common area with a common name syntax. It will also tag it some extra information such as who it is from, when it was committed and any comments that the author has provided.This is referred to as Publishing
Any artist who wishes to share his or her work must first Publish the material they wish to share. This ensures that all material in the common area align with each other in terms of the various conditions they must fulfill.
Error: Could not publish. Reason: Normals Locked!Uh uh. Seems Bob is having some trouble with his publish. It seems that before Bob may submit his work to the common area, he must first make sure that the normals on his models are unlocked. By fulfilling this criteria Bob will ensure that his work live up to the standards of every other model in the common area.
This critera is referred to as a Post-Condition
All models in the common area are guaranteed to live up to a set of post-conditions just like this one. The same applies assets of any species.
What is an Asset?
A film may be considered to be divided up into a set of Sequences and Shots, and each shot may contain one or more Assets.An Asset is a building-block of a film
It represents an entity, such as a character or a piece of furniture, along with information about that entity, such as its name, description, author and so on. All of it encapsulated into a unified whole, called an Asset.
Assets are at the very heart of Pipi. In fact: A shot can only consist of Assets
This means that before an animator, for instance, can make use of your beautifully sculpted model, it must first go through the rigorous set of tests and fulfill each of the post-conditions set for its species.
This enables artists to know what to expect when loading new material from Pipi and helps keep things neat.
Wednesday, January 9, 2013
Working in Context pt. 2
So how would you let your application know about the context? Well, there are a few ways. The most convenient way might be to try and find a common ground of communication between you and the application. A place where both you and the application could read and write to
So how does one access the environment? Well, it depends on your point of entry.
From the command line in Windows 7, you can go
And on Both Mac and Linux\Ubuntu using bash, you can go
We, however, are mainly interested in accessing it via Python
One variable you might already be familiar with is PATH. Which is, according to wiki.. "..a list of directory paths. When the user types a command without providing the full path, this list is checked if it contains a path that leads to the command." You usually store executables that you would like to run from a command line of sorts.
Another useful and common one is the PYTHONPATH. This is a variable which python looks for when determining which paths to use when searching for modules during import.
So, cmd.exe uses PATH to determine what executables are available and python uses PYTHONPATH. How about we make our own dependency? Couldn't we specify a CurrentProject variable that our library could use to determine which project we are in, in addition to Maya, Nuke, or any other program that might like to know about it? In this sense, CurrentProject is a global variable, accessible by everything that is run as a child of the OS.
Global is usually not the answer, however, but there is one thing that helps us with compartmentalization. Any time you open an application that needs the environment in any way, the environment is copied in to the running process. This means that modifying the environment from inside a child process is merely modifying it's own copy of the environment. It's own duplicate. You can think of this as a child process inheriting from its parent process.
This can be both a blessing and a curse. In some cases, it would be great to modify a variable and have all applications know about it so that they can update accordingly. But there are better ways around that. For instance, whenever a change occurs, a signal could be emitted to dependent processes to update accordingly. That way, not only can you control the flow of updates, but it also helps in keeping things tidy.
o Windows
o Terminal
o Maya
o Nuke
o Mari
Each level of this hierarchy is an opportunity to modify the environment, which means that we could separate modifications into groups related to the context in which it is getting modified. For example, the operating system could assign variables related to the overall operation of every application, independent of the user. The terminal then lets the user add to that via custom commands, such as setting the current project. Maya would then have a final copy with all of the information that it needs to operate.
But wait, there's more! In addition to these three levels of updating our environment, it can in fact happen at a few more levels.
o Boot
o Windows
o Login (per user)
o Launch Terminal (per terminal)
o Custom Commands
o Per Project
o Per Asset
o Maya
o Nuke
o Mari
As you can see, we can assign each of these level a responsibility and have a very dynamic way of interacting with our applications. Letting them know exactly what is going on with very little effort.
In the next part, I'll go through implementation and some of the problems I encountered along this path. Such as how to work around the fact that a process cannot edit it's parent environment.
Environment Variables
In most operating systems there is the concept of environment variables. A common-ground for all applications on your computer, most of which will only read from it but some who also writes to it. You can think of it as a file on disk that everything accesses whenever the user stores a setting or an application requests one. In programming terms, it can be thought of as a singleton or global variable.So how does one access the environment? Well, it depends on your point of entry.
From the command line in Windows 7, you can go
>>> set // Print all environment variables PROCESSOR_LEVEL=6 PROCESSOR_REVISION=3a09 ProgramData=C:\ProgramData ProgramFiles=C:\Program Files ProgramFiles(x86)=C:\Program Files (x86) ... >>> set windir // Print a single variable windir=C:\Windows >>> set myVariable=MyValue // Create a new variable and print it >>> set myVariable myVariable=MyValue
And on Both Mac and Linux\Ubuntu using bash, you can go
>>> env // Print all environment variables XDG_CURRENT_DESKTOP=Unity LESSCLOSE=/usr/bin/lesspipe %s %s LC_TIME=en_GB.UTF-8 COLORTERM=gnome-terminal XAUTHORITY=/home/marcus/.Xauthority LC_NAME=en_GB.UTF-8 _=/usr/bin/env ... >>> printenv XDG_CURRENT_DESKTOP // Print a single variable Unity >>> export myVariable=MyValue // Create a new variable and print it >>> printenv myVariable MyValue
We, however, are mainly interested in accessing it via Python
>>> import os >>> for key, value in os.environ.iteritems(): >>> print "%s=%s" % (key, value) // Print all environment variables XDG_CURRENT_DESKTOP=Unity LESSCLOSE=/usr/bin/lesspipe %s %s LC_TIME=en_GB.UTF-8 COLORTERM=gnome-terminal XAUTHORITY=/home/marcus/.Xauthority LC_NAME=en_GB.UTF-8 _=/usr/bin/env ... >>> os.environ['MyVariable'] = MyValue // Create a new variable and print it >>> print os.environ['MyVariable'] MyValue
One variable you might already be familiar with is PATH. Which is, according to wiki.. "..a list of directory paths. When the user types a command without providing the full path, this list is checked if it contains a path that leads to the command." You usually store executables that you would like to run from a command line of sorts.
Another useful and common one is the PYTHONPATH. This is a variable which python looks for when determining which paths to use when searching for modules during import.
So, cmd.exe uses PATH to determine what executables are available and python uses PYTHONPATH. How about we make our own dependency? Couldn't we specify a CurrentProject variable that our library could use to determine which project we are in, in addition to Maya, Nuke, or any other program that might like to know about it? In this sense, CurrentProject is a global variable, accessible by everything that is run as a child of the OS.
Global is usually not the answer, however, but there is one thing that helps us with compartmentalization. Any time you open an application that needs the environment in any way, the environment is copied in to the running process. This means that modifying the environment from inside a child process is merely modifying it's own copy of the environment. It's own duplicate. You can think of this as a child process inheriting from its parent process.
This can be both a blessing and a curse. In some cases, it would be great to modify a variable and have all applications know about it so that they can update accordingly. But there are better ways around that. For instance, whenever a change occurs, a signal could be emitted to dependent processes to update accordingly. That way, not only can you control the flow of updates, but it also helps in keeping things tidy.
What's next
So, we'd like to modify our environment to store information about the context and then have Maya et al. make use of it. How do we go about doing this?The terminal
Via the terminal, you can read the file system, create and edit files, folders. You can also modify the environment. This, in addition to the fact that the terminal contains a full copy of all environment variables, means that we can edit the environment inside the terminal and then start an application from it. This would make the terminal a child of the OS, and the application a child of the terminal. The OS would maintain it's own original of the environment, the terminal would contain a modified version and then this modified version would get passed along to Maya (which, in turn, would then make another duplicate of this environment). In fact, we could launch several processes via the terminal and each one would get the same modified copy of the environment from the parent, our terminal.o Windows
o Terminal
o Maya
o Nuke
o Mari
Each level of this hierarchy is an opportunity to modify the environment, which means that we could separate modifications into groups related to the context in which it is getting modified. For example, the operating system could assign variables related to the overall operation of every application, independent of the user. The terminal then lets the user add to that via custom commands, such as setting the current project. Maya would then have a final copy with all of the information that it needs to operate.
But wait, there's more! In addition to these three levels of updating our environment, it can in fact happen at a few more levels.
o Boot
o Windows
o Login (per user)
o Launch Terminal (per terminal)
o Custom Commands
o Per Project
o Per Asset
o Maya
o Nuke
o Mari
As you can see, we can assign each of these level a responsibility and have a very dynamic way of interacting with our applications. Letting them know exactly what is going on with very little effort.
In the next part, I'll go through implementation and some of the problems I encountered along this path. Such as how to work around the fact that a process cannot edit it's parent environment.
Subscribe to:
Posts (Atom)